
Setelah mengenal support vector regression, kita akan mencoba menggunakan model tersebut dengan library SKLearn. Dataset yang akan kita gunakan adalah data lama kerja seseorang dan gajinya. Dataset ini dapat diunduh pada tautan berikut.
Setelah mengunggah dataset yang sudah di-unzip pada Google Colaboratory, pada cell pertama notebook kita impor library dasar yang dibutuhkan. Jangan lupa untuk mengubah berkas csv dari dataset menjadi dataframe Pandas.
- import pandas as pd
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- data = pd.read_csv('Salary_Data.csv')
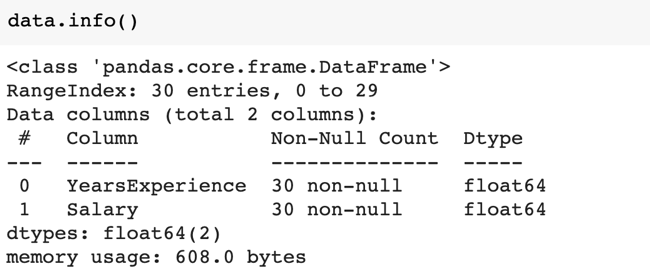
Selanjutnya kita bisa melihat apakah terdapat missing value pada dataset dengan fungsi .info(). Keluaran dari cell di bawah menunjukkan bahwa tidak ada missing value pada dataset.
- data.info()
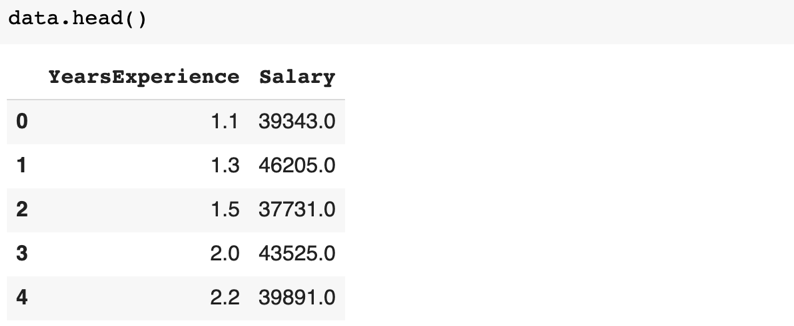
Selanjutnya kita tampilkan 5 baris pertama dari dataframe.
- data.head()
Kemudian kita pisahkan antara atribut dan label yang ingin diprediksi. Ketika hanya terdapat satu atribut pada dataframe, maka atribut tersebut perlu diubah bentuknya agar bisa diterima oleh model dari library SKLearn. Untuk mengubah bentuk atribut kita membutuhkan library numpy.
- import numpy as np
- X = data['YearsExperience']
- y = data['Salary']
- X = X[:,np.newaxis]
Berikutnya kita buat buat objek support vector regression dan di sini kita akan mencoba menggunakan parameter C = 1000, gamma = 0.05, dan kernel ‘rbf’. Setelah model dibuat kita akan melatih model dengan fungsi fit pada data.
- from sklearn.svm import SVR
- model = SVR(C=1000, gamma=0.05, kernel='rbf')
- model.fit(X,y)
Terakhir kita bisa memvisualisasikan bagaimana model SVR kita menyesuaikan terhadap pola yang terdapat pada data menggunakan library matplotlib.
- import matplotlib.pyplot as plt
- plt.scatter(X, y)
- plt.plot(X, model.predict(X))
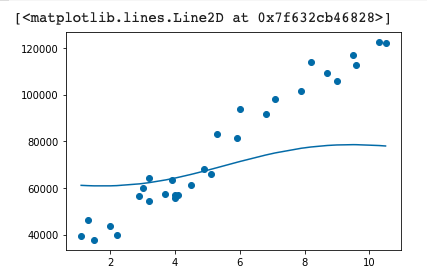
Hasil visualisasi menunjukkan bahwa model yang kita kembangkan, belum mampu menyesuaikan terhadap pola pada data dengan baik. Nah, pada modul berikutnya kita akan mencoba meningkatkan performa model kita dengan menggunakan grid search