

Salah satu bidang menarik yang muncul dari perkembangan machine learning adalah Computer Vision. Computer Vision adalah bidang yang memberi komputer kemampuan untuk ‘melihat’ seperti manusia.
Salah satu contoh implementasi dari computer vision adalah pada pengenalan wajah, bahkan deteksi penyakit. Dan salah satu bidang yang mulai populer yaitu self driving cars seperti di bawah ini.

Bagaimana komputer melihat?
Komputer adalah sebuah mesin yang hanya bisa membaca angka. Sebuah gambar dalam komputer adalah matriks yang berisi nilai dari setiap pixel di gambar. Pada gambar hitam putih, gambar merupakan matriks 2 dimensi, dan pada gambar berwarna gambar merupakan matrix 2 kali 3 dimensi di mana, 3 dimensi terakhir adalah jumlah kanal dari gambar berwarna yaitu RGB (red, green, blue).

Klasifikasi Gambar
Peran machine learning dalam computer vision adalah dalam klasifikasi gambar. Contohnya, kita punya label yaitu nama beberapa presiden Amerika Serikat. Kita ingin memprediksi siapa presiden di gambar. Pada jaringan saraf seperti di bawah adalah probabilitas dari siapa presiden di dalam foto.
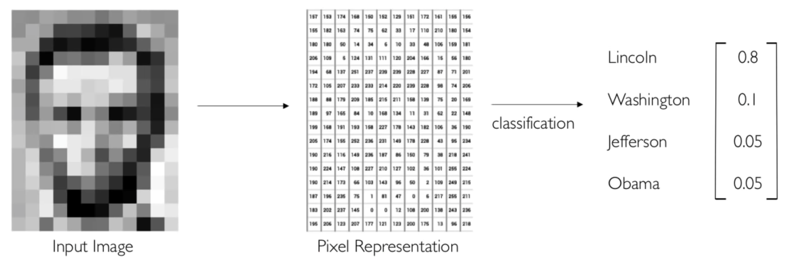
Untuk mengklasifikasikan siapa presiden dalam gambar dengan benar, model kita harus mampu untuk mengenali ciri-ciri unik yang terdapat pada wajah Lincoln, Washington, Jefferson, dan Obama.

Setiap objek dari gambar memiliki atribut unik. Seperti pada gambar di atas, objek orang memiliki atribut hidung, mata, dan mulut. Pada objek gambar terdapat atribut roda, lampu, dan plat nomor.
Convolutional layer berfungsi untuk mengenali atribut-atribut unik pada sebuah objek.
Convolutional Layer
Sebuah jaringan saraf biasa mengenali gambar berdasarkan piksel-piksel yang terdapat pada gambar.
Teknik yang lebih optimal adalah dengan menggunakan convolutional layer di mana alih alih mengenali objek berdasarkan piksel-piksel, jaringan saraf dapat mengenali objek berdasarkan atribut-atribut yang memiliki lebih banyak informasi.
Teknik yang lebih optimal adalah dengan menggunakan convolutional layer di mana alih alih mengenali objek berdasarkan piksel-piksel, jaringan saraf dapat mengenali objek berdasarkan atribut-atribut yang memiliki lebih banyak informasi.
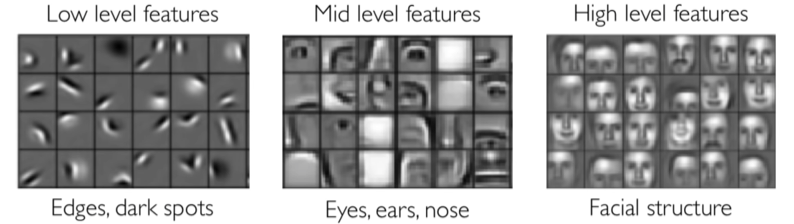
Convolutional layer membantu jaringan saraf untuk mengenali objek seperti orang berdasarkan atribut-atributnya. Atribut-atribut yang lebih rendah membentuk atribut lebih tinggi contohnya atribut wajah dibentuk dari atribut mata, telinga, dan hidung. Atribut mata dibentuk dari garis, lengkungan dan bintik hitam.
Filter
Convolutional layer dapat mengenali atribut pada objek menggunakan filter. Filter hanyalah sebuah matriks yang berisi angka-angka.
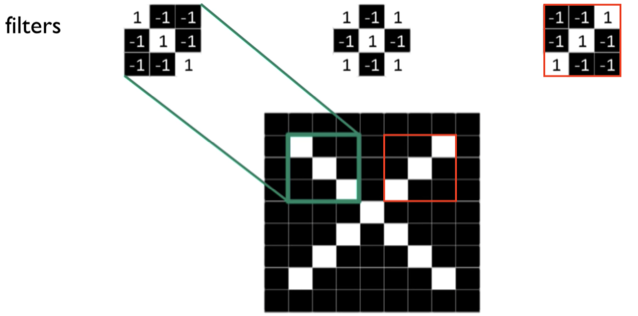
Pada gambar di bawah terdapat 3 buat filter masing-masing merupakan matriks 3x3 dan sebuah objek yaitu gambar berisi huruf X.
Filter yang berada di sebelah kiri digambarkan dapat mengenali garis yang terdapat pada kotak hijau. Setiap filter berbeda dapat mengenali atribut yang berbeda seperti, filter di kanan dapat mengenali atribut objek x yang berada di kotak merah.
Pada gambar di bawah terdapat 3 buat filter masing-masing merupakan matriks 3x3 dan sebuah objek yaitu gambar berisi huruf X.
Filter yang berada di sebelah kiri digambarkan dapat mengenali garis yang terdapat pada kotak hijau. Setiap filter berbeda dapat mengenali atribut yang berbeda seperti, filter di kanan dapat mengenali atribut objek x yang berada di kotak merah.
Contoh lain dari filter dapat Anda lihat di bawah. Pada sebuah gambar perempuan, aplikasi dari filter yang berbeda menghasilkan gambar yang berbeda.
Kita dapat membedakan seekor kuda dan manusia berdasarkan bentuknya bukan? Nah, dengan filter seperti pada gambar yang paling kanan, kita dapat mendeteksi garis-garis yang bisa menunjukkan apakah seseorang merupakan kuda atau manusia berdasarkan bentuk garisnya.

Proses Konvolusi
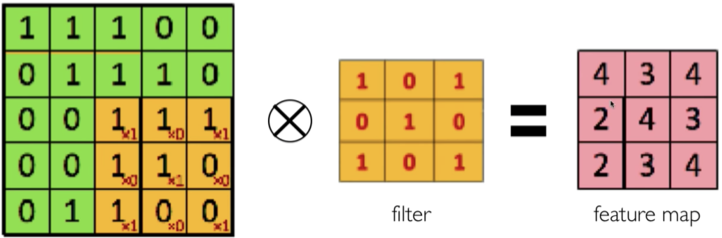
Proses konvolusi adalah proses yang mengaplikasikan filter pada gambar. Pada proses konvolusi ada perkalian matriks terhadap filter dan area pada gambar.
Pada ilustrasi di bawah terdapat sebuah gambar, filter, dan hasil dari proses konvolusi terhadap gambar. Animasi selanjutnya menunjukkan bagaimana proses konvolusi pada ilustrasi sebelumnya dikerjakan.
Pada ilustrasi di bawah terdapat sebuah gambar, filter, dan hasil dari proses konvolusi terhadap gambar. Animasi selanjutnya menunjukkan bagaimana proses konvolusi pada ilustrasi sebelumnya dikerjakan.
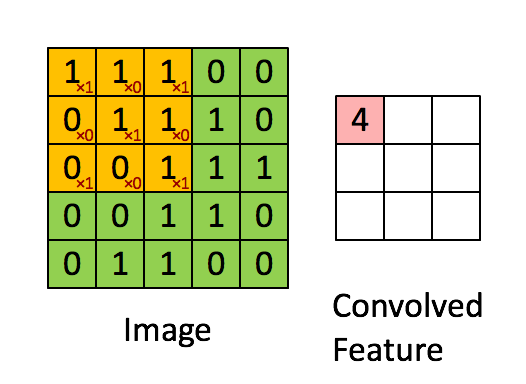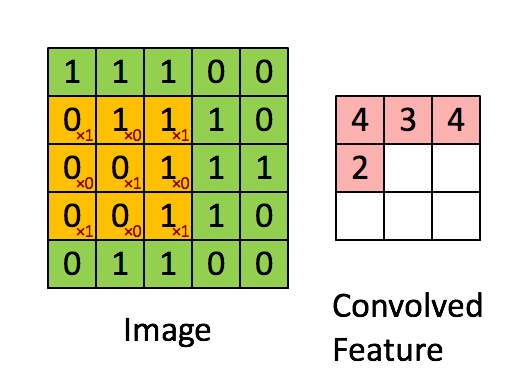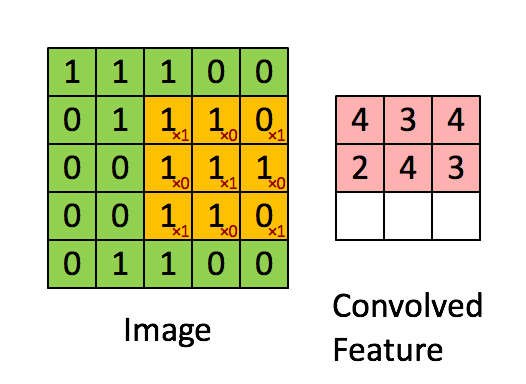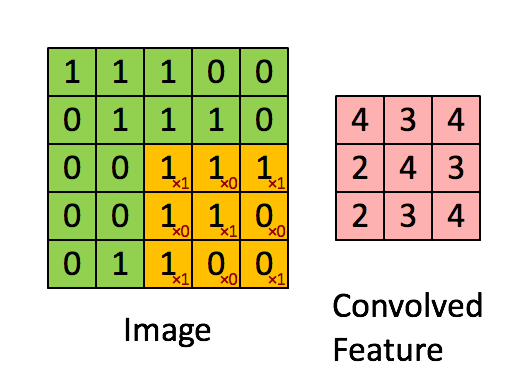
Ketika proses konvolusi selesai, hasil dari konvolusi tersebut dapat dijadikan masukan untuk sebuah MLP.
Max Pooling
Pada sebuah jaringan saraf tiruan, umumnya setelah proses konvolusi pada gambar masukan, akan dilakukan proses pooling.
Pooling adalah proses untuk mengurangi resolusi gambar dengan tetap mempertahankan informasi pada gambar.
Contohnya seperti pada gambar berikut di mana ketika resolusi dikurangi sampai batas tertentu kita masih bisa mendapatkan informasi mengenai objek pada gambar.
Pooling adalah proses untuk mengurangi resolusi gambar dengan tetap mempertahankan informasi pada gambar.
Contohnya seperti pada gambar berikut di mana ketika resolusi dikurangi sampai batas tertentu kita masih bisa mendapatkan informasi mengenai objek pada gambar.
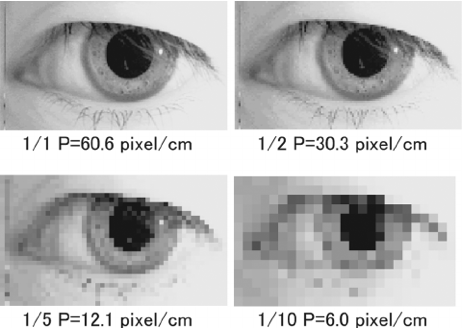
Salah satu contoh dari pooling adalah max pooling. Pada max pooling, di antara setiap area dengan luas piksel tertentu, akan diambil satu buah piksel dengan nilai tertinggi. Hasilnya akan menjadi gambar baru.
Animasi di bawah menunjukkan contoh max pooling dengan ukuran 2x2 piksel pada gambar berukuran 4x4 piksel. Hasil dari max pooling adalah gambar dengan ukuran 2x2 piksel.
Animasi di bawah menunjukkan contoh max pooling dengan ukuran 2x2 piksel pada gambar berukuran 4x4 piksel. Hasil dari max pooling adalah gambar dengan ukuran 2x2 piksel.
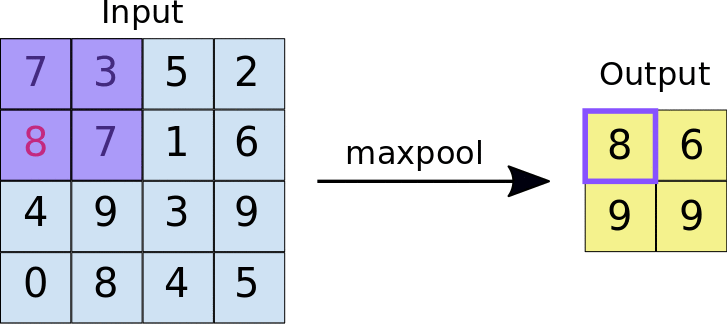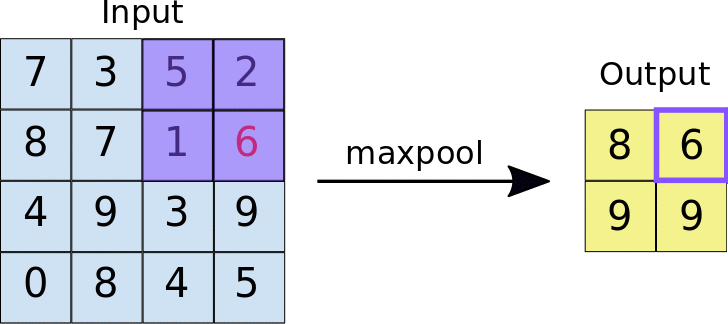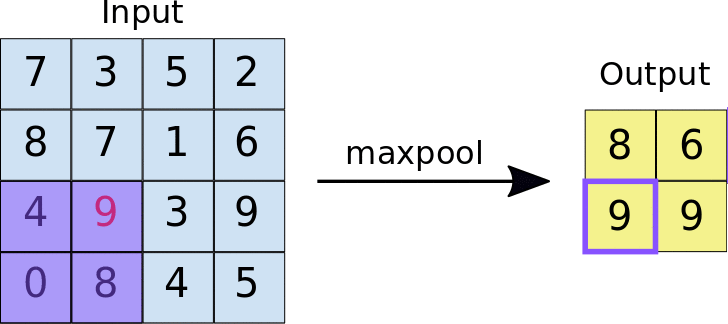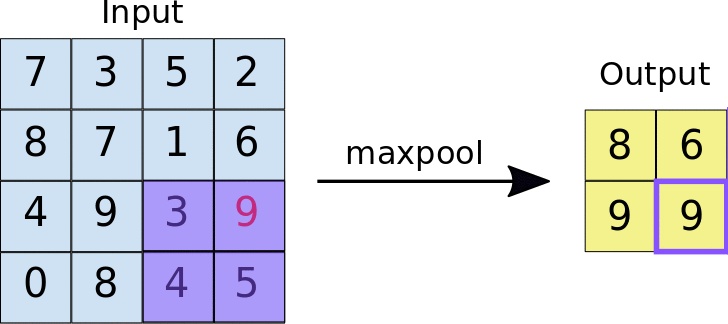
Proses max pooling dipakai karena pada praktiknya, jumlah filter yang digunakan pada proses konvolusi berjumlah banyak. Ketika kita menggunakan 64 filter pada konvolusi makan akan menghasilkan 64 gambar baru. Max pooling membantu mengurangi ukuran dari setiap gambar dari proses konvolusi
Convolutional Neural network
Arsitektur CNN adalah sebuah jaringan saraf yang menggunakan sebuah layar konvolusi dan max pooling. Pada arsitektur CNN di bawah, sebuah gambar masukan dideteksi atribut/fitur nya dengan menggunakan konvolusi 3 filter.
Lalu setelah proses konvolusi akan dilakukan max pooling yang menghasilkan 3 buah gambar hasil konvolusi yang memiliki resolusi lebih kecil. Terakhir, hasil max pooling dapat dimasukkan ke dalam sebuah hidden layer MLP.
Lalu setelah proses konvolusi akan dilakukan max pooling yang menghasilkan 3 buah gambar hasil konvolusi yang memiliki resolusi lebih kecil. Terakhir, hasil max pooling dapat dimasukkan ke dalam sebuah hidden layer MLP.
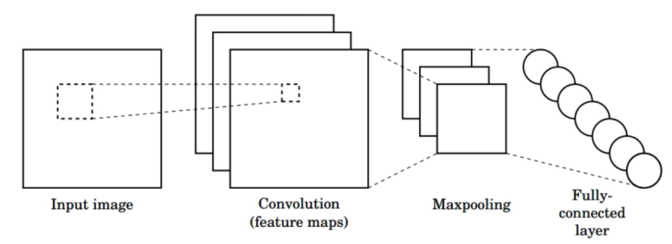 Kita juga dapat menggunakan beberapa lapis konvolusi dan max pooling sebelum mulai memasukkannya ke hidden layer sebuah MLP. Cara kerjanya sederhana. Kita bisa melakukan proses konvolusi dan max pooling setelah lapisan max pooling sebelumnya. Pada contoh di bawah terdapat 2 kali proses konvolusi dan max pooling sebelum hasilnya dimasukkan ke dalam hidden layer.
Kita juga dapat menggunakan beberapa lapis konvolusi dan max pooling sebelum mulai memasukkannya ke hidden layer sebuah MLP. Cara kerjanya sederhana. Kita bisa melakukan proses konvolusi dan max pooling setelah lapisan max pooling sebelumnya. Pada contoh di bawah terdapat 2 kali proses konvolusi dan max pooling sebelum hasilnya dimasukkan ke dalam hidden layer.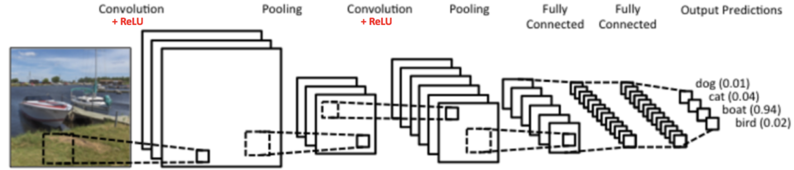
Dengan beberapa lapis proses konvolusi, makin detail fitur yang dapat dikenali dari gambar.
Contohnya pada proses konvolusi pertama dapat mendeteksi wajah pada dari seorang manusia.
Lalu pada proses konvolusi kedua, wajah hasil konvolusi pertama dapat dideteksi fitur yang lebih detail seperti hidung, mata, dan telinganya. Jika Anda ingin mengetahui lebih detail mengenai CNN, Anda dapat mengunjungi tautan berikut yah.
Contohnya pada proses konvolusi pertama dapat mendeteksi wajah pada dari seorang manusia.
Lalu pada proses konvolusi kedua, wajah hasil konvolusi pertama dapat dideteksi fitur yang lebih detail seperti hidung, mata, dan telinganya. Jika Anda ingin mengetahui lebih detail mengenai CNN, Anda dapat mengunjungi tautan berikut yah.
Selamat!. Sekarang Anda paham cara kerja CNN dan fungsinya dalam deteksi gambar. Di modul berikutnya kita akan praktik mengembangkan sebuah CNN dengan TensorFlow