

Library Scikit Learn menyediakan fungsi untuk membagi dataset menjadi train set (data training) dan test set (data testing).
Pada Colab kita import library yang dibutuhkan.
- import sklearn
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
Library sklearn menyediakan dataset iris yakni sebuah dataset yang umum digunakan untuk masalah klasifikasi. Dataset ini memiliki jumlah 150 sampel. Untuk mendapatkan dataset, kita bisa menulis kode berikut pada cell baru.
- iris = datasets.load_iris()
Dataset iris dari library sklearn belum dapat langsung dipakai oleh sebuah model ML. Sesuai dengan yang telah dibahas pada modul terdahulu, kita harus memisahkan antara atribut dan label pada dataset.
- x=iris.data
- y=iris.target
Untuk membuat train set dan test set kita tinggal memanggil fungsi train_test_split. Train_test_split memiliki parameter x yaitu atribut dari dataset, y yaitu target dari dataset, dan test_size yaitu persentase dari test
set dari dataset utuh. Train_test_split mengembalikan 4 nilai yaitu, atribut dari train set, atribut dari test set, target dari train set, dan target dari test set.
- x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
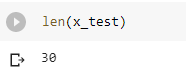
Ketika kita print panjang dari x_test, kita bisa melihat bahwa panjang dari atribut test set adalah 30 sampel, sesuai dengan parameter yang kita masukkan pada fungsi train_test_split yaitu 0.2 atau 20% dari 150 sampel. Kode untuk print panjang dari x_test seperti di bawah ini
- len(x_test)
Pada tahap ini dataset kita sudah bisa dipakai pada sebuah model machine learning